考完信息安全数学基础来填坑qwq
主要内容:
- 残差网络结构
- ResNet网络结构
- BN详解
- 迁移学习概述
RetNet网络亮点:
- 超深的网络结构(突破1000层)
- 提出residual模块
- 使用Batch Normalization加速训练(丢弃dropout)
好热QAQ
提出背景
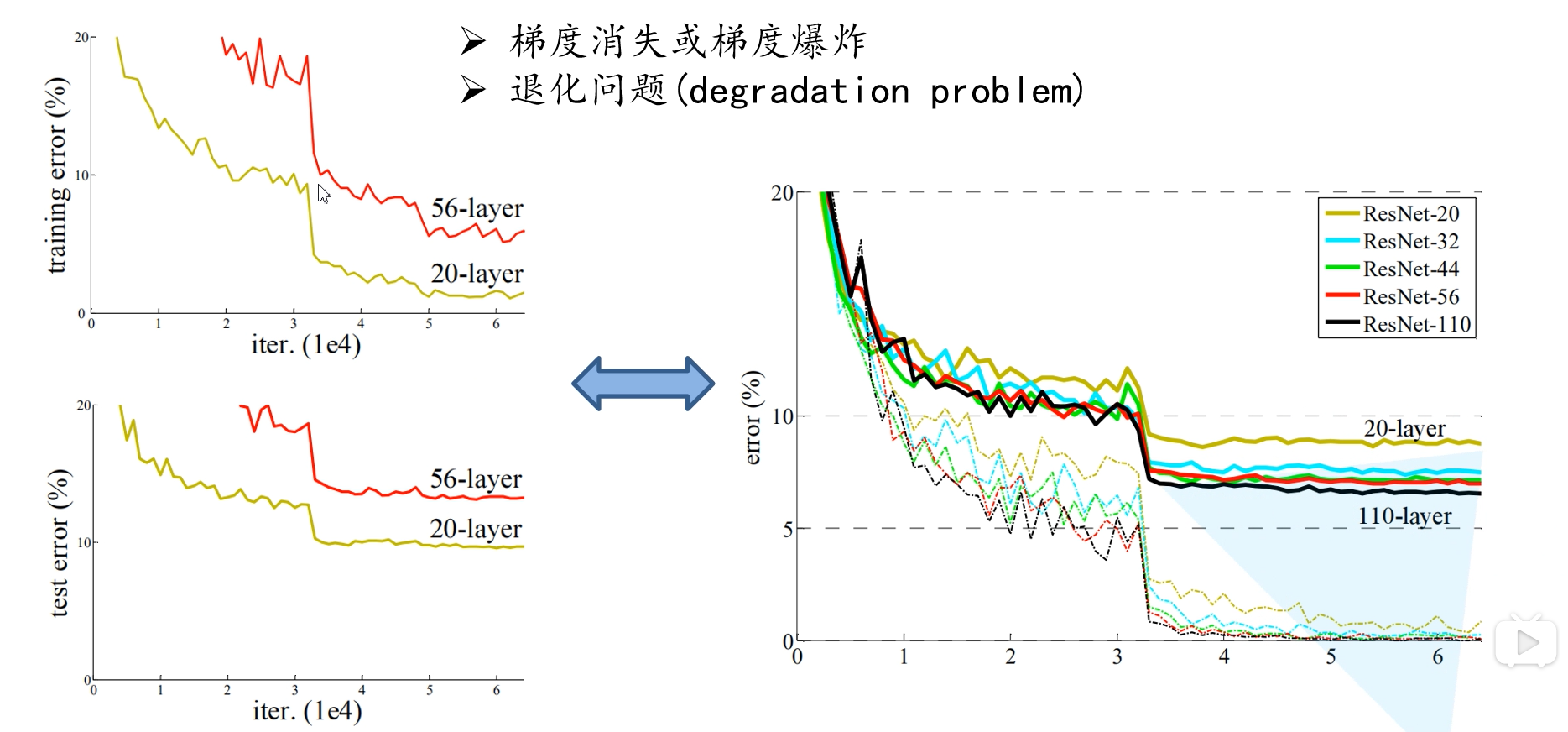
从图中可以看出,更深的网络效果不一定好
- 梯度消失或梯度爆炸问题
梯度消失:假设每层误差梯度小于1,则在反向传播过程中,每向前传播一次,都要乘一个小于1的数,随着网络的加深,这个数越接近于0.
梯度爆炸: 如果每层误差梯度大于1,则在反向传播过程中,每向前传播一次,都要乘一个大于1的数,随着网络的加深,这个数变得特别大。
解决办法:对数据进行标准化处理、权重初始化、BN - 退化问题
解决办法:残差结构
残差网络结构
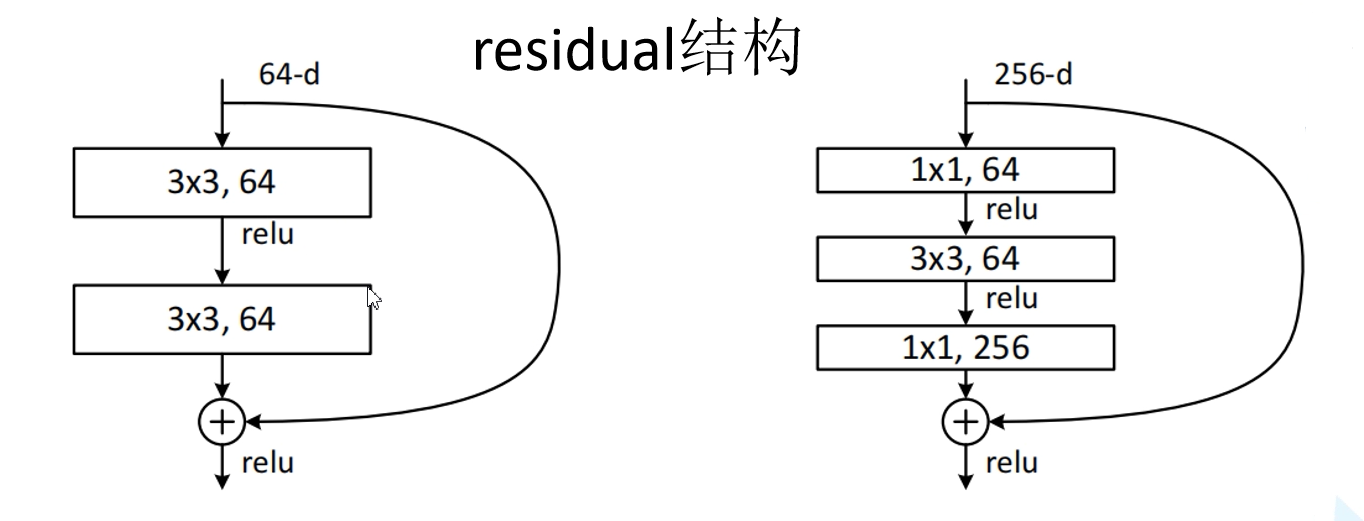
左边残差结构适用于层数较少的网络,如ResNet-34,输入的特征矩阵先经过两个$3\times 3$的卷积层,然后与原特征矩阵相加。
右面残差结构适用于层数较多的网络,如ResNet-50/101/152,输入的特征矩阵经过$1\times 1$的卷积层进行降维,然后经过$3\times 3$的卷积层,最后通过$1\times 1$的卷积层进行升维,并与原特征矩阵相加。其中两个$1\times 1$的卷积层起到升降维的作用。
注意:主分支与shortcut的输出特征矩阵shape必须相同。
假设输入特征矩阵深度都为256,则所需参数个数分别为:
- 左:$3\times 3\times 256\times 256+3\times 3\times 256\times 256=1179648$
- 右:$1\times 1\times 256\times 64+3\times 3\times 64\times 64+1\times 1\times 64\times 256=69632$
ResNet网络结构
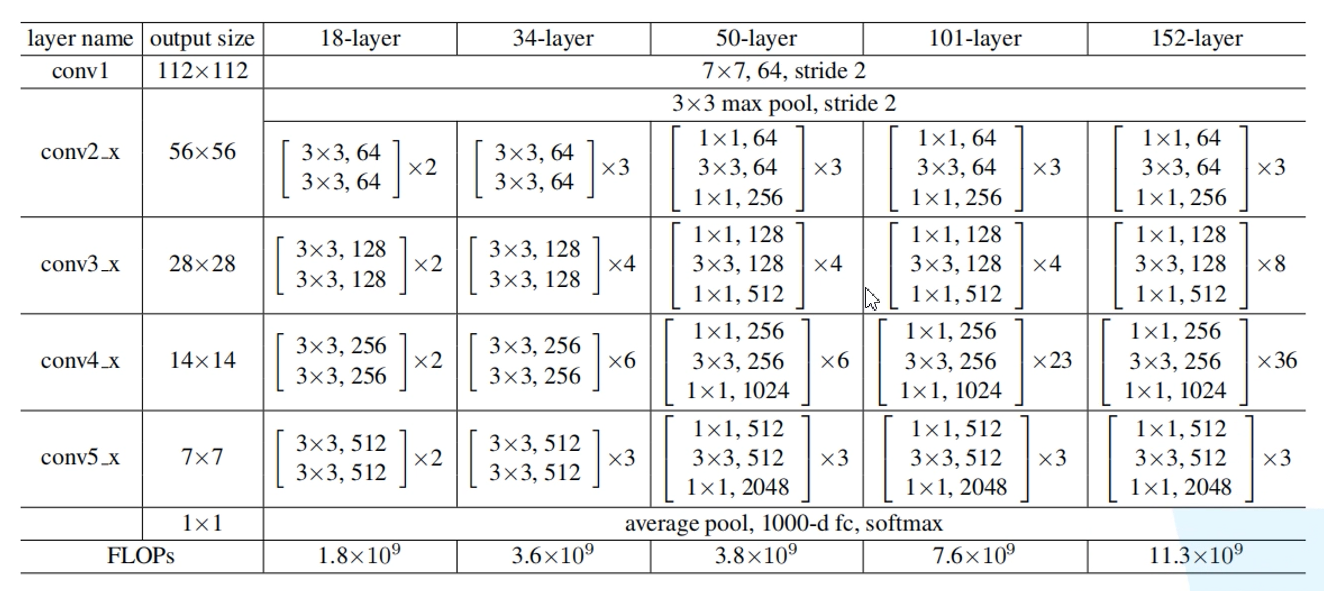
其中残差结构的shortcut虚线与实线的区别: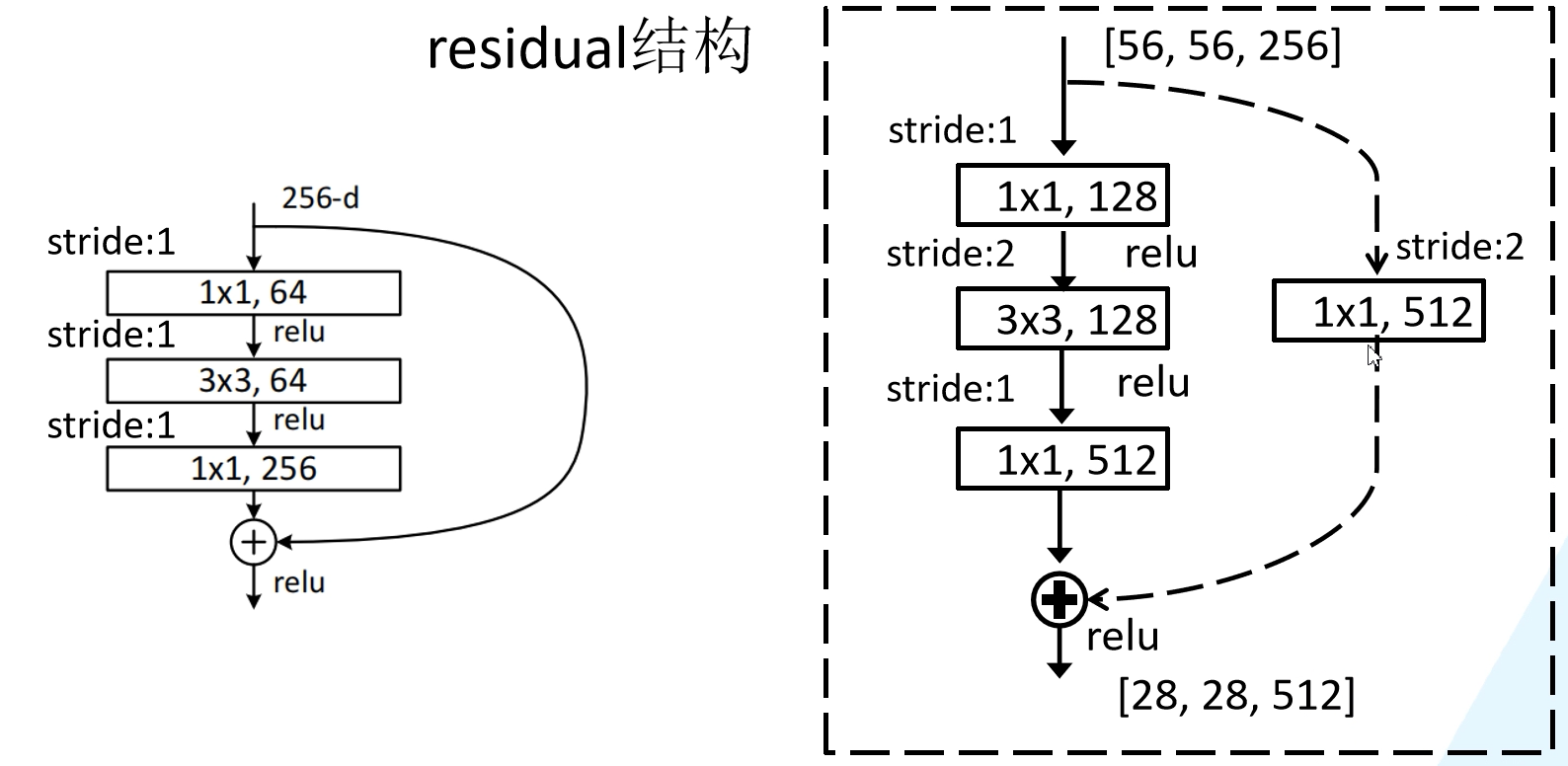
实线的shortcut没有改变特征矩阵形状,直接将特征矩阵与主分支相加,而虚线的shortcut通过卷积层改变特征矩阵形状,使其输出与主分支形状相同。
其中conv3-5的第一个残差结构的shortcut都是虚线,50/101/152-layer的conv2的第一个残差结构的shortcut也为虚线。
Batch Normalization详解
目的:使一批(Batch)feature map(特征矩阵的每个维度)满足均值为0,方差为1的分布规律。
具体操作:对于整个batch而言:
$\mu$为均值,$\sigma^2$为方差,是正向传播中统计得到
$\epsilon$避免方差为0
$\gamma$和$\beta$分别对方差和均值进行调整,是通过反向传播中训练得到
注意事项:
- 训练时将training参数设置为true,验证时将training参数设置为false。
- batch size尽可能大,batch size越大,所求的均值和方差越接近整个数据集的均值和方差。
- 最好将BN层放在卷积层和激活层中间,此时卷积层的bias没有用。
https://blog.csdn.net/qq_37541097/article/details/104434557
迁移学习简介
一个预训练的模型被重新用在另一个任务中
优势:
- 能够快速训练出一个理想的结果
- 在数据集较小时也能训练出一个理想的结果
注意预处理方法
常见方法:
- 载入权重后训练所有参数(参数不受限且结果最优)
- 载入权重后只训练后几层参数(时间短或参数有限)
- 载入权重后在原网络上再添加一层全连接层,仅训练最后一个全连接层(时间短或参数有限)